Metasploitable2 in vagrant
It’s interesting to me how much time I just spent figuring out how to do something I just did two (three?) years ago.
Back then, I started working on a “devops” approach to a virtual machine kali pentest lab. That meant documenting
– and scripting, as far as possible – each step. DevOps starts from as early in the chain as possible – from an installation iso (starting with packer in that case), a vagrant base box, or for Metasploitable2, the Rapid-7 “golden-image” vmdk file. And ending with the deployed vagrant images that I have students use.
Except apparently I didn’t document anything about how I made a libvirt vagrant provider Metasploitable2. I could have vagrant-migrated one of the metasploitable2 boxes on vagrantcloud built for different providers. But that felt
too fragile – too far removed from the origin. And why take the easy road when you can spend 10x as long
doing it yourself!
There were some show-stopper problems. The interesting part is that when I hit these gotchas, I had no recollection of hitting them before. But I did have my already-working Metasploitable2 libvirt box to reference. It was basically my own golden image on top of the Rapid7 golden image – a disk that I got working at one point, but couldn’t replicate the steps. It “just worked.” That’s anti-devops.
So I’d hit a problem, and then scratch my head and say, “well how did I do it with this golden image?”. But few hints jumped to mind. So I found myself starting from ground zero – web-searching* promising pieces of the error messages, combing through forums, curating potential solutions using my fathomless life experiences. I’d look at a potential solution and then say, “this looks promising… does it look like I did this with the golden image?” and if yes, I applied the step to the original image, created a new vagrant box, and saw whether it worked.
For example, look at this error:
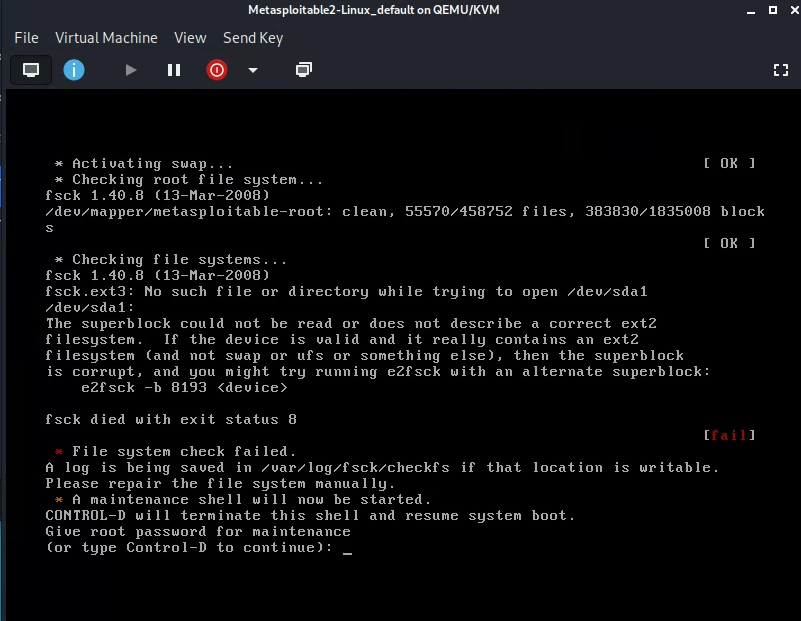
My hints:
- When I created an image in virt-manager by using the metasploitable2 vmdk source disk directly, this error did not appear.
- However, when I used
qemu-img convertto change the .vmdk to a .qcow2 format, followed by using this create_box.sh script to package the qcow2 into a vagrant box, then followed byuping a new vagrant instance referencing that box, the above error appeared.
Suspicion: Was qemu-img convert corrupting the disk?
- Test: I created a vm instance directly from the qcow2 file created by
qemu-img convert. The error did not appear. - Conclusion: No,
qemu-img convertwas not corrupting the disk.
Suspicion: Was create_box.sh corrupting the disk?
- Test: I examined the source code. It didn’t do anything noteworthy to the disk – it basically just bundled the disk alongside vagrantfile defaults.
Suspicion: Were the vagrantfile defaults set by create_box.sh messing things up?
- Test: I looked at documentation for each default that was set. I also looked at output during
vagrant upon the working vagrant box for differences. No differences found. - Conclusion: the vagrantfile wasn’t impacting anything.
Suspicion: I remembered something nagging about /etc/fstab, from previous boxes I’d made. I then read the error message in
the image above more closely. It wasn’t saying
the disk was necessarily corrupt. Rather, it was saying it couldn’t find /dev/sda.
- Hrm! That aligned with my nagging about
/etc/fstab. I looked for differences between the broken and goldendevice_bussettings from virt-manager details inspector. One was IDE and the other was VirtIO. Whatvagrant-libvirtsettings drove that difference? Could that be the issue? How does the OS know what kind of device is mounted? - I skimmed lightly through the
vagrant-libvirtandlibvirtdocumentation for things related to the disk. Ah! VirtIO mounts the disk as/dev/vda, while IDE mounts it as/dev/sda. And indeed, there was an entry in the broken-image/etc/fstablooking for thesdavariant. And in the golden image, I had apparently changed it to look forvda. - Generalizable solution: I deleted that
/etc/fstabentry from the base vmdk, then re-converted and re-vagrant-packaged and re-added. This worked.
Solved.
I had to go through similar troubleshooting to realize that msfadmin needed passwordless-sudo so that vagrant-libvirt
could ssh in and add a second network adapter. That took another few hours, but lo, it turns out I had done that in the golden image
at some point. No memory of that! Weird! But I remembered – from hints while web-searching – that that was a common step required when setting the conventional vagrant user on a vagrant base box.
Again, meta-cognitively, the interesting part was my having no memory of having already done these steps. Maybe I’m getting old. Or maybe I did the original steps so late at night that they hadn’t entered long-term memory, if that is a thing. :shrug:
I have documented the build process in this github repo.
* trying my best to not say “google-searching”. Except, duckduckgo sucked at guessing
that I was looking for the vagrant-libvirt project landing page – its github repo – when I searched vagrant-libvirt – that repo’s
readme is the seventh hit for that search. Where the root of the repo is the
first hit for a google search. So, hat tip to google for coding searching, I guess.

Dave Eargle is a Senior Consultant in Cybersecurity Assessment at Carve Systems. More about the author →
This page is open source. Please help improve it.
Edit